
Announcing Indexify
Build Production-Grade LLM Applications that React to Your Data

Build Production-Grade LLM Applications that React to Your Data
Have you built a prototype with LLMs lately? Chances are you spent most of your time tuning the accuracy of your application. But do you trust its reliability? Will it be snappy enough to keep your users engaged? Will it be adaptive to new models or new modalities of data?
Even if you've built a great demo, scaling it to production is the real challenge. The transition from prototype to live environment of data processing infrastructure is fraught with systems engineering challenges and performance issues. Enter Indexify: the tool that changes the game by simplifying the transition from prototype to production for data-intensive LLM applications at any scale.
If you want to dive straight into code, here is our GitHub repository!
The Missing Piece of LLM Infrastructure Stack
Traditionally, applications have used structured data stores like Postgres and APIs. With the rise of LLMs, there's a need for decision-making software and personalized assistants that derive knowledge from real-world data such as videos, PDFs, images, and emails. Among all currently available tools, batch processing systems like Spark and Hadoop best process unstructured data. However, they aren't designed for low-latency, privacy-aware online systems. Recent LLM frameworks make prototyping LLM applications easier, but they don't provide a robust, reliable, and scalable data infrastructure needed to process unstructured data at scale or handle all types of unstructured data.
What are we trying to solve?
We hope to address many of the issues developers face when they transition from prototype to production of a data-intensive LLM application. In our experience, this starts with three key challenges:
- Seamlessly integrate embedding and structured data extraction pipelines.
- Maintain updated indexes for dynamic data changes.
- Ensuring fault tolerance throughout the ingest-extract-retrieve process as data volume grows.
- Data Infrastructure that spans across GPUs and CPUs and scaling with data.
We built Indexify to enable LLM applications to adapt to their evolving environments through real-time pipelines that process real-world data. Indexify excels in real-time data extraction, multi-modality, retrieval, and scales with data. It supports the ingestion of various data types and the construction of pipelines for vector and structured databases, streamlining both structured data retrieval and semantic search under a single API.
Unparalleled flexibility between Vector and Structured Data
Today's RAG applications mainly use flexible but less accurate semantic search on embedding for retrieval. Retrieving accurate context for LLMs from a large corpus of documents, videos, or images using semantic search involves re-ranking, clustering, re-writing queries, and fine-tuning embedding models. Tuning such an end-to-end system takes a lot of time and work.
Structured data extracted from the same sources makes it easy to retrieve accurate context by transforming queries to SQL queries. Associating structured data with embedding also improves semantic search. You can narrow down the search space by applying predicates on the structured data associated with the embeddings before performing the semantic search.
Imagine building a financial research assistant — you could create an extraction pipeline that extracts metadata such as ticker names, dates of reports, and other key information. Retrieving context targeting specific dates or company names becomes easier by writing the query as an SQL statement that filters the report's criteria. Using only semantic search would require getting the top 50 document fragments, re-ranking them, and praying that the LLM does not use the data from the irrelevant fragments.
Indexify makes the interplay between vector and structured data easy by syncing vector stores with structured data automatically when it detects presence of both in a single pipeline.
Data is constantly changing.
Indexify is the only framework that provides true real-time extraction.
For optimal performance, LLM applications must adapt instantly to dynamic data changes, ensuring real-time responsiveness and accurate answers. Indexify provides accurate answers for frequently updated documents by synchronizing data changes with indexes through real-time extraction pipelines.
Building reporting or decision-making tools on real world events, business transactions, and conversations becomes a breeze.
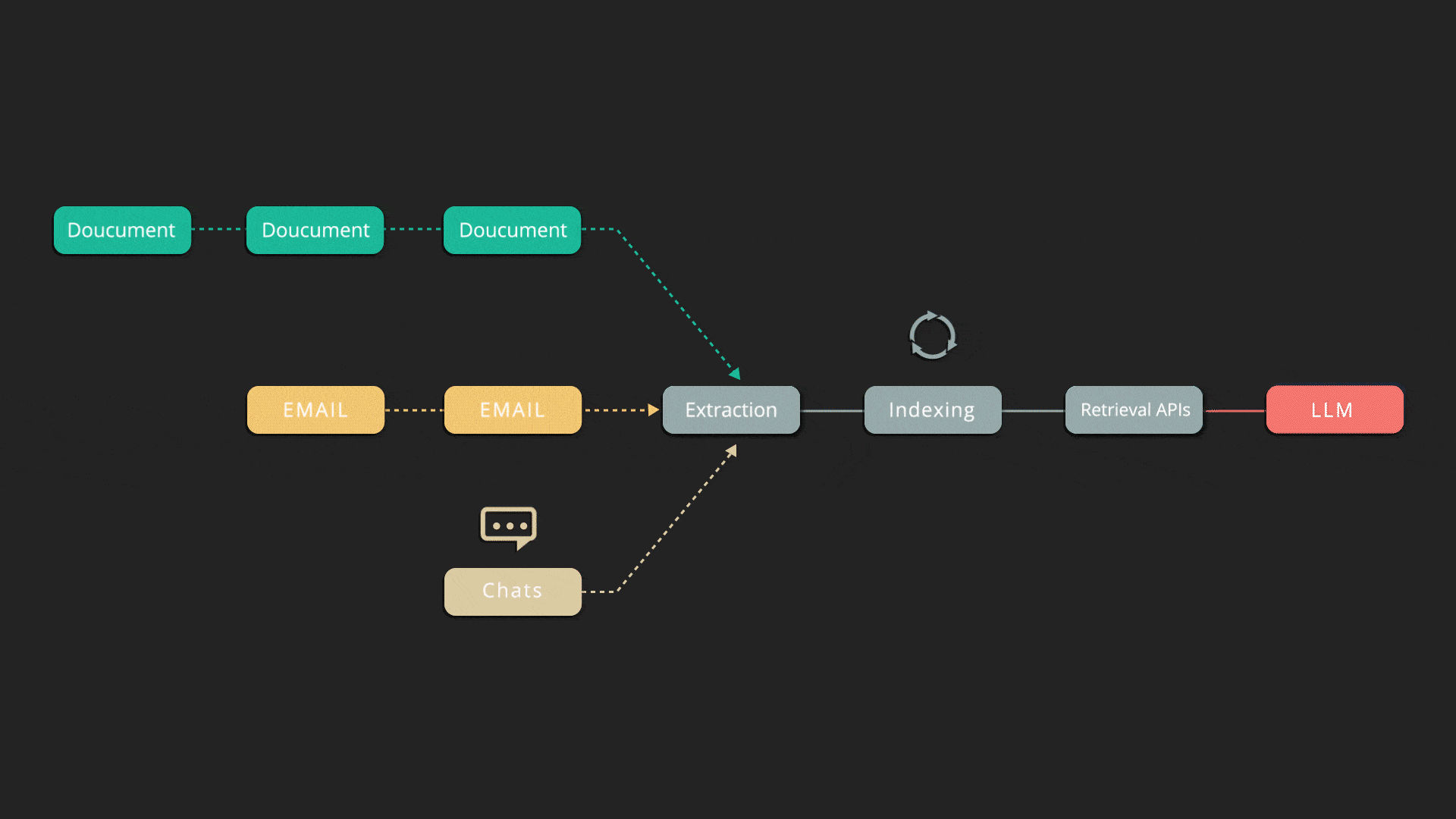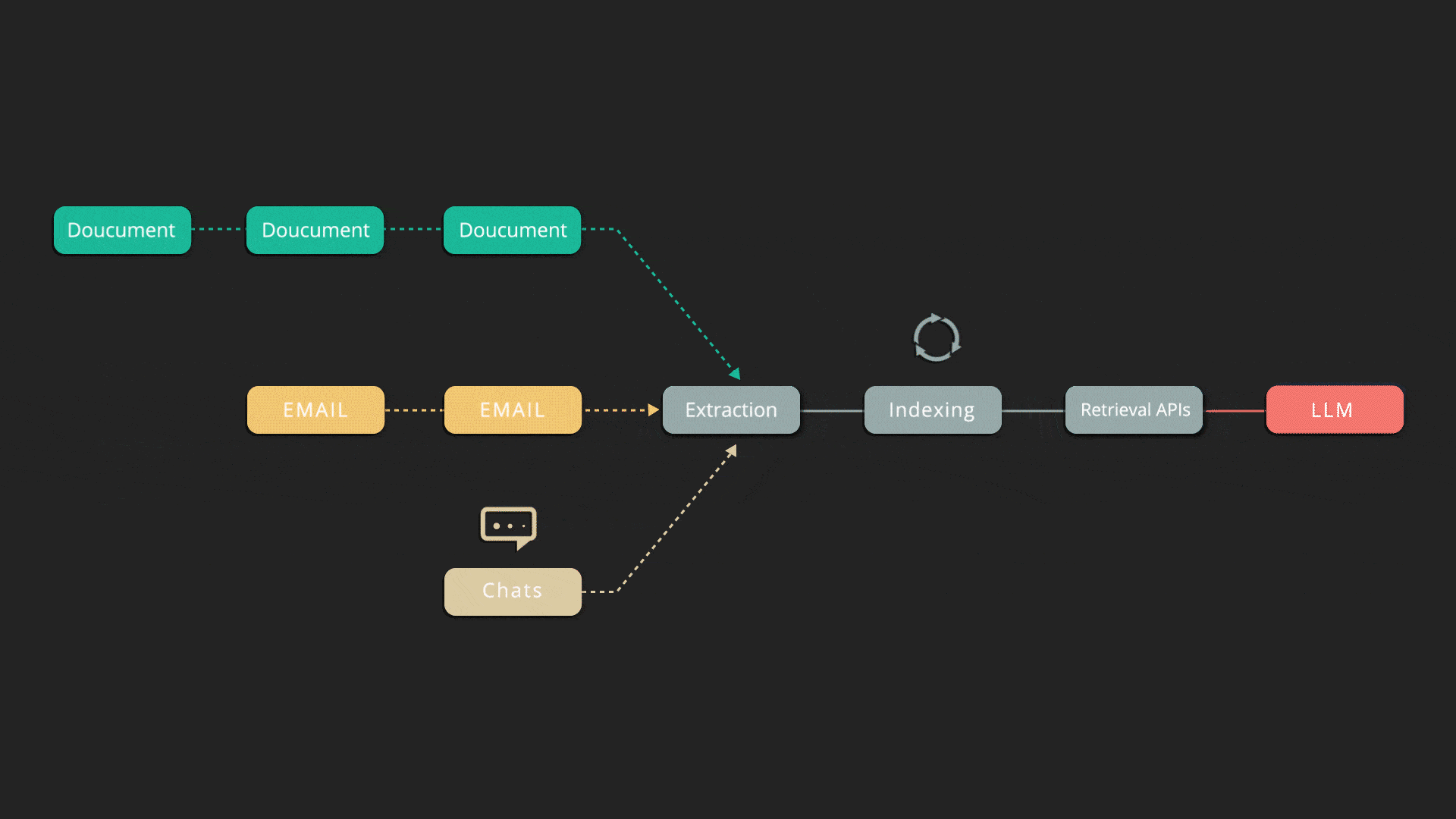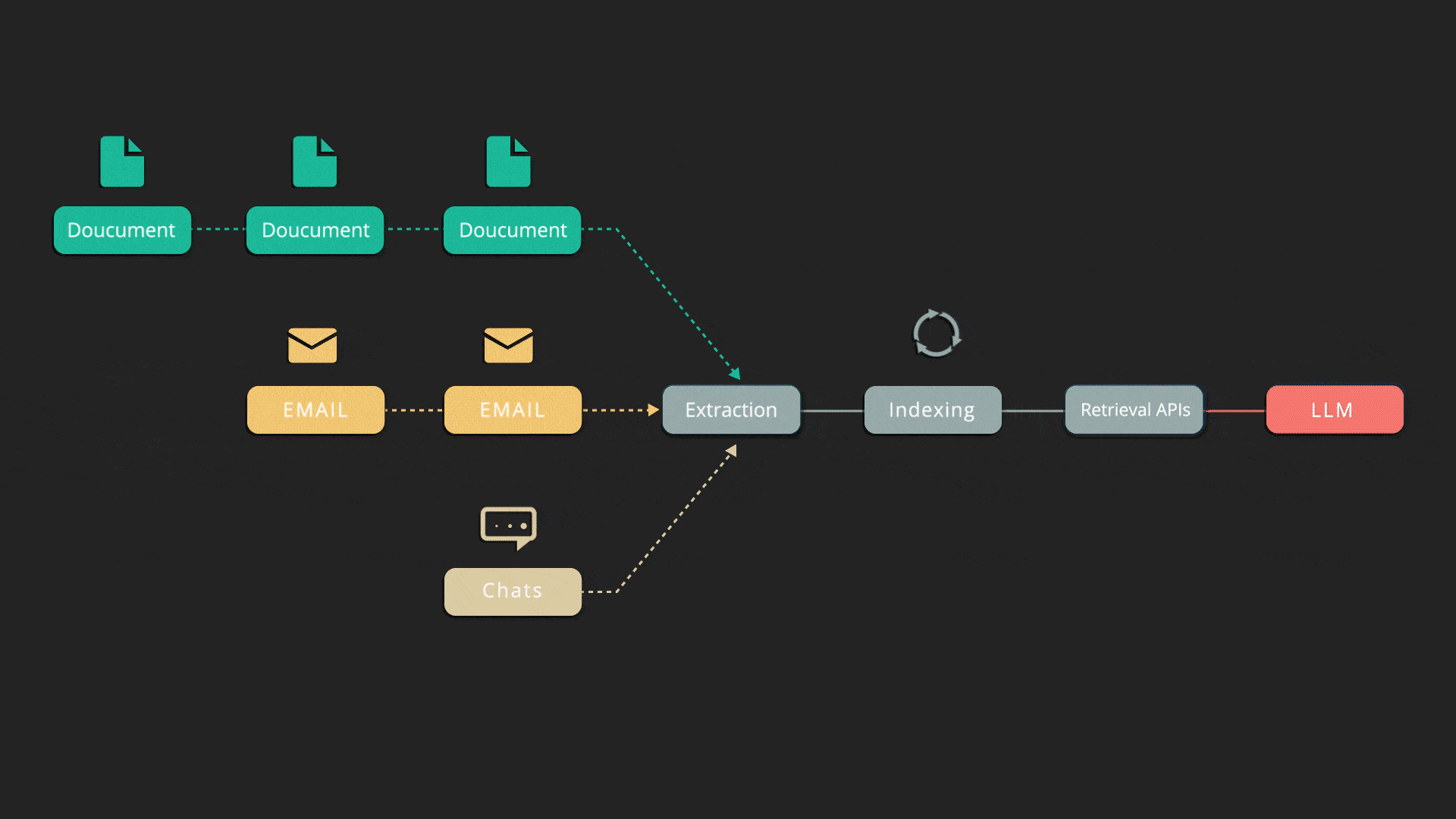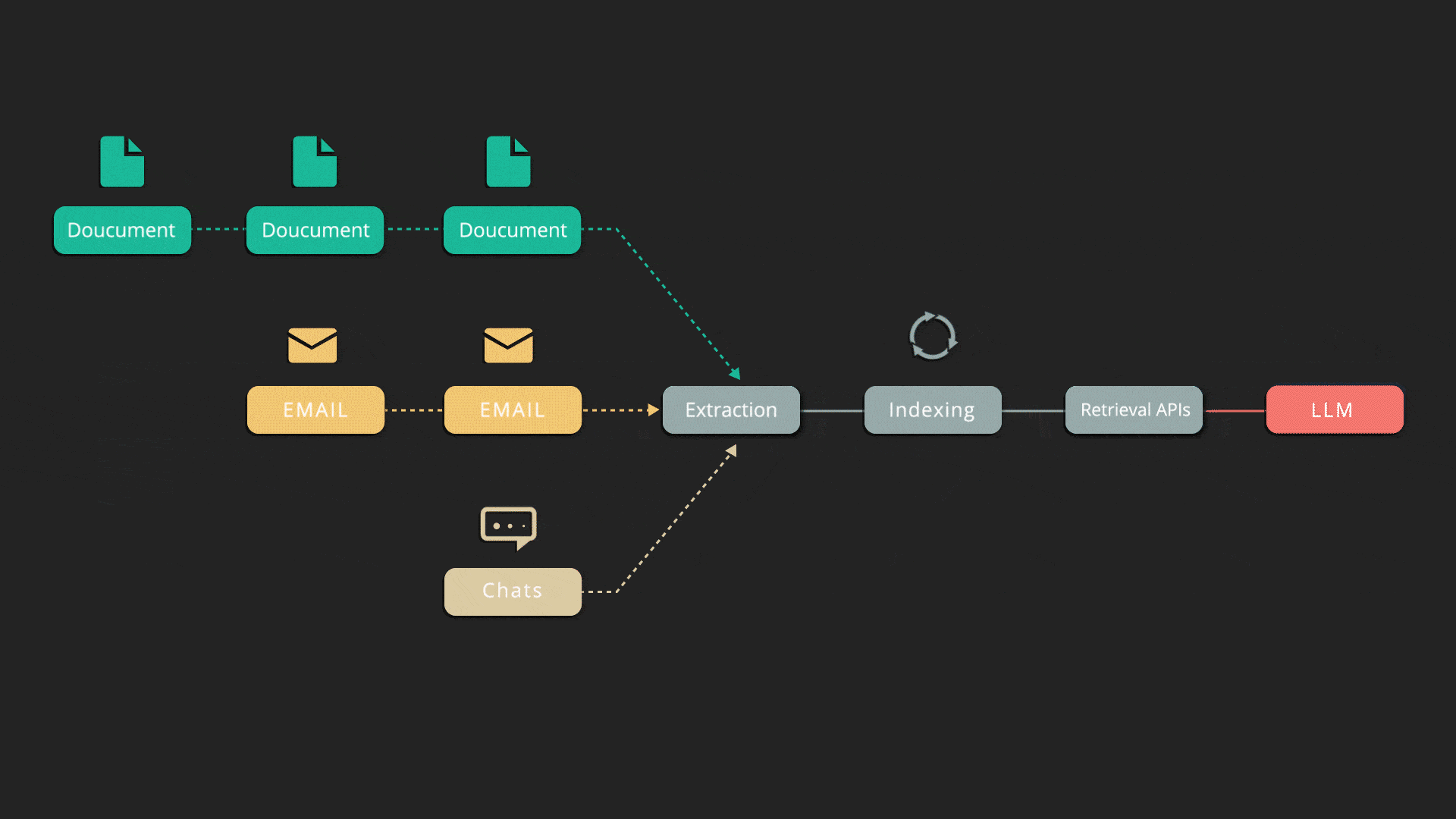
Deletion and Incremental Indexing
Indexify automatically deletes data from various indexes and structured stores when the source is deleted, ensuring compliance with privacy-related regulations. When data sources are partially updated, it only recomputes and syncs the changed parts with storage systems.
Real-Time Compute Engine
We designed Indexify for real-time performance. The reactive engine starts execution in less than five milliseconds. Near instant execution means your LLM will know about the changes in a document or uptake transcripts from a sales call as they happen. The compute engine is built on top of a replicated state machine, which allowed us to develop a fault-tolerant control plane without the overheads of polling a database like Postgres or Redis to react to new data.
While many developers turn to queues for extraction workloads, they often become impractical, and allocating compute resources becomes challenging when engineers or workloads share clusters. To remedy this, we developed a shared state scheduler in Indexify. With scalability comparable to the largest internet systems, you won't encounter scalability limits anytime soon, making Indexify the ideal long-term solution.
Fault Tolerance for Business Critical Applications
The difference between indexing a document and dropping it on the floor because of a transient error in the system is a happy user versus losing your user's trust. Indexify's state machine for extraction allows computations to be expressed as pipelines, where each step is durable, and failures are automatically retried. The control plane itself can be replicated within a geographical region, thus making it resilient to failures of compute nodes or whole data center failures.
Multi-Modality to Future Proof Your Applications
In a business, there are more than just PDFs. Soon, you will need to draw information from emails, videos, and images for your LLM applications. Indexify provides a unified interface for extracting information from all forms of unstructured data so that you don't have to change tools and frameworks when the time comes. We have included a variety of pre-built and optimized extractors for the most common forms of data. You can also build and share your own custom extractors for use cases that are unique to your application.
Extracting audio, embedding, or structured data from a 3-hour-long video could yield gigabytes of derived data. Naive ingestion methods over HTTP request/response fails in such cases. We have developed a streaming protocol that allows extracting and ingesting any arbitrary amount of extracted data.
Fits Seamlessly into the LLM Infrastructure Stack
It works with popular LLM Frameworks
Indexify won't limit you; it doesn't require applications to be built with a specific LLM framework or programming language. You can use Indexify with HTTP APIs or our Python and TypeScript libraries. We have built Langchain and DSPy integrations to simplify using Indexify as a retriever within these frameworks, providing seamless connectivity and streamlining the retrieval process.
Integrates with All Your Favorite Databases
Indexify integrates with Qdrant, Pinecone, PgVector, and LanceDB for vector storage. We use blob stores to store raw unstructured data instead of vector stores to allow for scalable reads and writes of large files. Indexify supports Postgres and SQLite, the most popular structured data storage systems, and additional storage backend support is coming soon.
Multi Geography Deployments — Extract and Query from Anywhere
It's becoming increasingly common to have distributed infrastructure for AI workloads to get capacity at reasonable prices. Indexify supports geo-distributed deployments, meaning the data plane for extraction can be deployed anywhere on any cloud, and the control plane can be centralized in a specific region. We use mTLS to encrypt all the traffic between control and data planes to secure data movement over the Internet.
What can You Do with it Today?
You can create pipelines to parse, summarize, embed, classify, and detect entities in videos, images, and documents, ideal for environments where data constantly evolves and LLMs make crucial decisions on the latest information.
If you start using Indexify for these use-cases today, it will scale with growing data volumes, allow you to integrate new models into your pipeline with a few lines of code, and facilitate pipeline deployment wherever you have capacity. Additionally, it provides metrics to troubleshoot performance issues related to retrieval and extraction.
The Future
In this post, we've explored many of Indexify's features and how they can help users. Stay tuned for future updates, where we will examine Indexify's internals and unveil all the ways you can use them!
We have only just begun our journey and can't wait to share more with you. Keep an eye out for our future improvements that will include:
- Robust security primitives for retrieval enable the easy building of privacy-sensitive applications.
- Probing hardware for automatic distribution of tasks across many different hardware accelerators to optimize for throughput, latency, and cost.
- Integration with more AI Native storage systems — Weviate, MongoDB, Cassandra, PineCone, etc.
- TypeScript SDK for writing extractors.
Do you have any ideas about where we should go or what we should build next?
Join our Discord to connect with us directly and build the future of open-source data processing for Generative AI with us!
Indexify's website — https://tensorlake.ai
Stay in touch with us by following us on Twitter and LinkedIn!