


Stopping Runaway Generation: A Production Solution for VLM Table Parsing

How we built a streaming detection and recovery system to handle repetition failures in vision-language model on document parsing.
TL;DR
Vision-language models, especially OCR-focused VLMs built with smaller language backbones, often enter infinite repetition loops when parsing sparse tables and forms, causing extreme latency and missing content in production systems.
While improved training data and model architectures will help reduce these failures over time, real-world deployments need robust handling today. We built a two-phase runtime solution:
- real-time detection to stop runaway generation early, and
- an iterative image-masking recovery loop that progressively extracts missed regions.
This approach reduced worst-case latency from 60s+ to ~10–20s and reliably recovered all tables on problematic documents—without impacting normal pages.
The Problem Everyone Faces
Vision-language models(VLMs) used for document parsing can enter infinite repetition loops when processing sparse tables and forms, Instead of stopping at empty rows or blank fields, the model repeatedly generates empty structures (e.g. <td></td>) until it hits the maximum token limit.
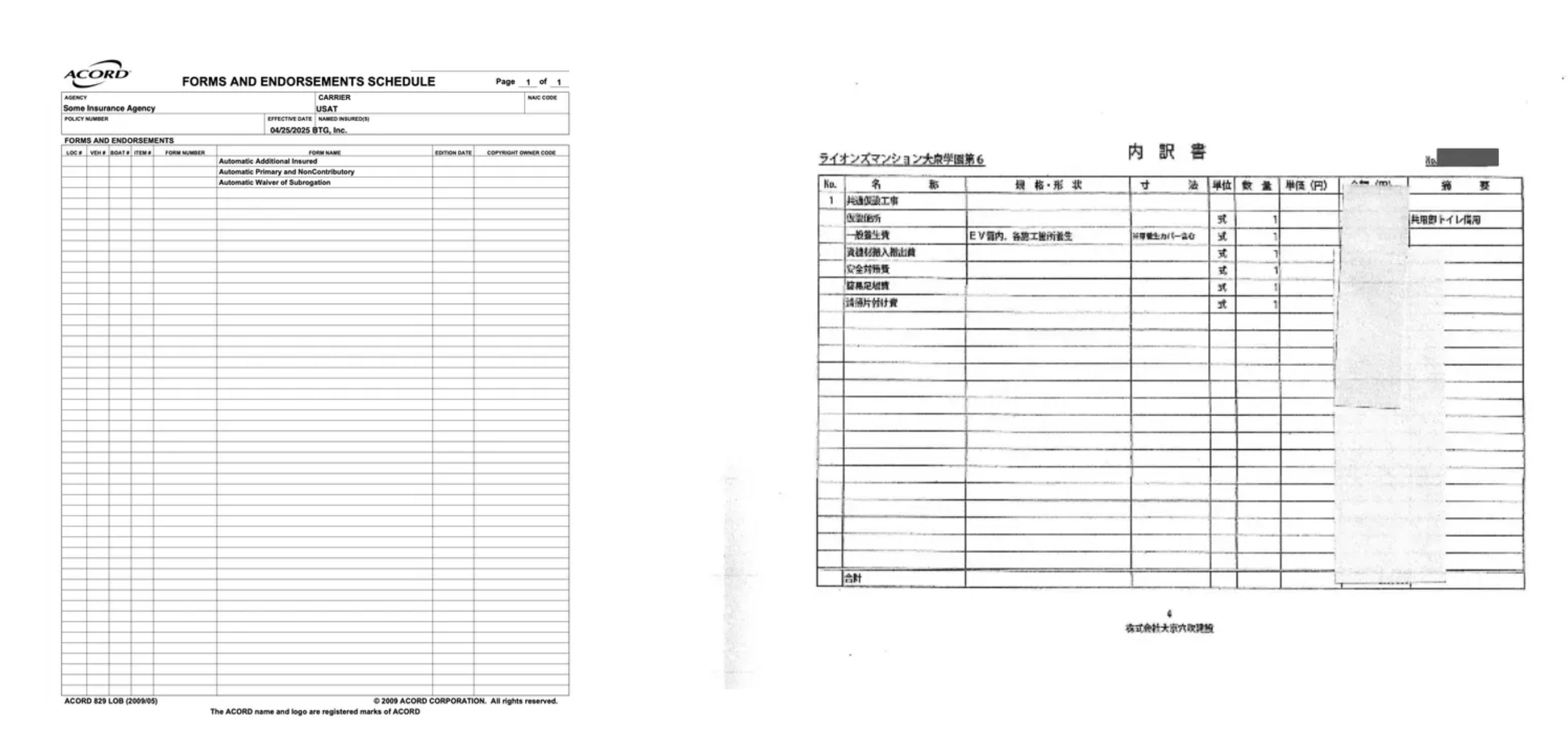
These documents are common in real workflows, and they are exactly where naive VLM pipelines might fail.
This isn’t a glitch of one model or one dataset. It’s a fundamental limitation of autoregressive VLMs when handling low-information visual regions.
And it’s especially painful in production, because these are exactly the documents you can’t ignore:
- partially filled forms
- invoice templates
- sparse tables with variable-length blank rows
You can’t pre-enumerate every possible repetition pattern in advance. Dots, underscores, empty cells, separators — the surface form varies endlessly.
Here’s how we addressed it.
Why VLMs Get Stuck in Loops
The issue stems from how vision-language models process structured documents:
1. Uniform Visual Signals
Blank form fields with dotted lines look nearly identical to the vision encoder. The model can't distinguish between "3 empty rows" and "30 empty rows"—they produce the same visual embeddings.
2. Autoregressive Amplification
Once the model generates <td></td> a few times, each subsequent token increases the probability of generating it again. With no visual variation to break the pattern, the model spirals into repetition.
3. Training Distribution Gap
Most VLMs are trained on filled forms and complete tables. They've rarely seen documents with extensive blank regions, so they lack learned patterns for when to stop generating empty cells.
The result? Your document processing fails on the exact documents that need the most help, partially filled forms, templates, and invoices with variable-length line items.
Our Approach: Real-Time Detection + Intelligent Recovery
We built a system that does two things:
- Detect runaway generation as it happens
- Recover missing content instead of giving up
Stopping bad generation is important — but recovery is what makes the system production-ready.
Phase 1: Pattern-Agnostic runtime Repetition Detection
Instead of waiting for generation to finish (or time out), we stream the model output and analyze it in real time.
The core insight:
Repetition failures have a distinctive signature:
- a short or medium-length pattern
- repeated many times
- dominating the recent output
Rather than hard-coding specific tokens or structures, we detect repetition as an emergent behavior.
How It Works (High Level)
During streaming generation:
- Maintain a sliding window over recent output
- Search for repeating substrings of varying lengths
- Measure:
- how many times the pattern repeats consecutively
- how much of the window it occupies
- Trigger early termination when repetition dominates
Key design choices:
- Exact matching avoids false positives on legitimate structured output
- Content checks distinguish empty markup from real extracted text
- Dual triggers catch both short, high-frequency loops and longer repeated sequences
When triggered, generation stops immediately — typically within a few seconds instead of tens of seconds.
This alone saves significant latency and compute.
Why Pattern-Agnostic Detection Matters
This approach works regardless of:
- token types (HTML, punctuation, whitespace)
- pattern length (a few characters to hundreds)
- document language or layout
That’s critical in real systems, where:
- invoices repeat dots
- forms repeat underscores
- tables repeat empty cells
You don’t know the failure pattern ahead of time — and you shouldn’t need to.
Phase 2: Iterative Masking for Content Recovery
Stopping early is only half the solution. The real innovation is what happens next: targeted recovery.
Here's the approach:
- Identify the failure point: The last layout element before repetition started is where content extraction failed. We mark this region for special handling.
- Progressive masking: We white out all successfully extracted regions on the original image, creating a "masked" version that highlights only unprocessed areas.
- Focused retry: Run the model again on the masked image. Now it sees a much simpler page with only the problematic region visible, making successful extraction much more likely.
- Intelligent merging: Combine results from the original attempt and retry(s), deduplicating overlapping regions and keeping the best content.
- Iterate if needed: If repetition still occurs, mask additional regions and retry—typically 2-3 iterations resolve even the worst cases.
Why this works: Each iteration progressively simplifies the page, allowing the model to focus on smaller regions without the visual noise of already-extracted content. It's like giving the model a "second chance" with better context.
Results on Production Documents
Example: Multi-Table Document Recovery

Detection and recovery on a production document containing five tables.
- Before:
- One table extracted, then runaway repetition on blank rows
- → 60s+ latency, incomplete output
- After:
- All five tables extracted via iterative masking
- → ~20s total, complete extraction
(Document content blurred for privacy. Colored boxes indicate detected table regions.)
Production Performance Summary

Across production traffic, ~90% of pages complete in a single pass with no intervention.
The recovery loop activates only on the remaining ~10% of problematic pages, where it consistently recovers missing tables with 2-3 retries.
Key Insights from Production Deployment
1. Real-Time Detection Is Mandatory
Waiting for generation to finish wastes time and money.
Streaming detection lets you intervene seconds into a failure that would otherwise run for a full minute.
2. Recovery Beats Prevention
We explored decoding-time fixes and sampling constraints.
They either degraded normal extraction or failed on edge cases.
Recovery-based approaches activate only when needed and leave good generations untouched.
3. False Positives Are Worse Than False Negatives
Stopping a valid extraction breaks downstream systems.
Missing a repetition just costs extra time.
We tuned aggressively to ensure zero false positives on legitimate documents.
4. Observability Enables Iteration
Logging repetition patterns, trigger conditions, and recovery paths revealed:
- which document types are most fragile
- where masking helps the most
- when fallback strategies are needed
This data turned a brittle system into a measurable, improvable one.
5. Know Where Recovery Has Limits
The recovery loop improves extraction reliability in many real-world cases, but it depends on the model being able to perceive the relevant regions at least once.
For documents with extremely poor image quality or highly ambiguous layouts, retries may still fail to extract certain structures. In practice, early stopping remains valuable by preventing runaway latency and returning partial, usable output.
Conclusion
Repetitive generation breaks document AI systems on the exact documents that matter most—sparse forms and partially filled tables. Traditional approaches either fail silently or waste time on full timeouts.
Our two-phase system—streaming detection + iterative masking—turns these failures into reliable extractions with bounded latency. The key insight: when models fail, don't just stop—actively recover the missing content.
If you're building production document AI, this challenge is inevitable. The good news: it's solvable with the right detection and recovery strategy.
Building production ML systems? We're solving problems like this daily.
Follow us @Tensorlake for more insights on real-world AI deployment.

Related articles

Get server-less runtime for agents and data ingestion

Tensorlake is the Agentic Compute Runtime the durable serverless platform that runs Agents at scale.
“With Tensorlake, we've been able to handle complex document parsing and data formats that many other providers don't support natively, at a throughput that significantly improves our application's UX. Beyond the technology, the team's responsiveness stands out, they quickly iterate on our feedback and continuously expand the model's capabilities.”
"At SIXT, we're building AI-powered experiences for millions of customers while managing the complexity of enterprise-scale data. TensorLake gives us the foundation we need—reliable document ingestion that runs securely in our VPC to power our generative AI initiatives."
“Tensorlake enabled us to avoid building and operating an in-house OCR pipeline by providing a robust, scalable OCR and document ingestion layer with excellent accuracy and feature coverage. Ongoing improvements to the platform, combined with strong technical support, make it a dependable foundation for our scientific document workflows.”
"For BindHQ customers, the integration with Tensorlake represents a shift from manual data handling to intelligent automation, helping insurance businesses operate with greater precision, and responsiveness across a variety of transactions"
“Tensorlake let us ship faster and stay reliable from day one. Complex stateful AI workloads that used to require serious infra engineering are now just long-running functions. As we scale, that means we can stay lean—building product, not managing infrastructure.”
